
Bits of interest on local AI
Docker Model Runner and Apple Silicon, local code auto-completion, Llama 4 not so bad for Apple users and more.

I've been thinking about local AI and I'm planning to consolidate and synthesize my thoughts on the ecosystem separately. But, for now I thought I'd share some notes on some things that have caught my eye in this area recently.
Docker Model Runner and Apple Silicon
Docker recently launched Docker Model Runner, a plugin for Docker Desktop users for pulling models from the DockerHub container registry and running them locally with OpenAI compatible APIs for chat completions and embeddings.
The most interesting part from the announcement is that the plugin can run models with GPU acceleration on Apple Silicon. This means that macOS developers can max out local model inference performance in containerized apps with less friction. Docker Desktop only supports GPU acceleration on Windows with Nvidia GPUs so previously, the easiest way to start using Apple Silicon for local model inference was to run Ollama standalone in addition to your containerized app. Now, an existing Docker Desktop user can do the same thing without running additional software. The Docker team clarified that this feature is enabled via host-based execution meaning that the model does not actually run in the container (due to performance degradation), but they've just abstracted away the machinery for connecting containers with models running on the host.
The product seems be a direct competitor to Ollama as a local model management UI/UX layer for developers (they also both wrap llama.cpp as the underlying inference engine) and is initially targeting the relatively underserved macOS developer community.
Qwen2.5-Coder-7b for local code auto-completion
The Qwen2.5 Coder models have been popular amongst AI enthusiasts for local coding tasks (i.e. see SimonW's blog post covering his experience running the 32B variant on a 64GB MacBook Pro M2), but I was curious about whether the smaller models like the 7b variant that can run on lower end machines (i.e. M1) are useful for anything.
It turns out the answer is yes! A few folks, including ggerganov, have reported positive experiences using Qwen2.5-Coder-7b for local, fast code auto-completion. If you compare against coding tasks performed by Claude-3.7-Sonnet in Cursor, Cline, etc. then auto-completion obviously feels underwhelming. A better reference to compare against is Cursor's Tab model. I'm excited for a future of local, unmetered, tab tab tab.
Llama 4 not so bad for Apple users?
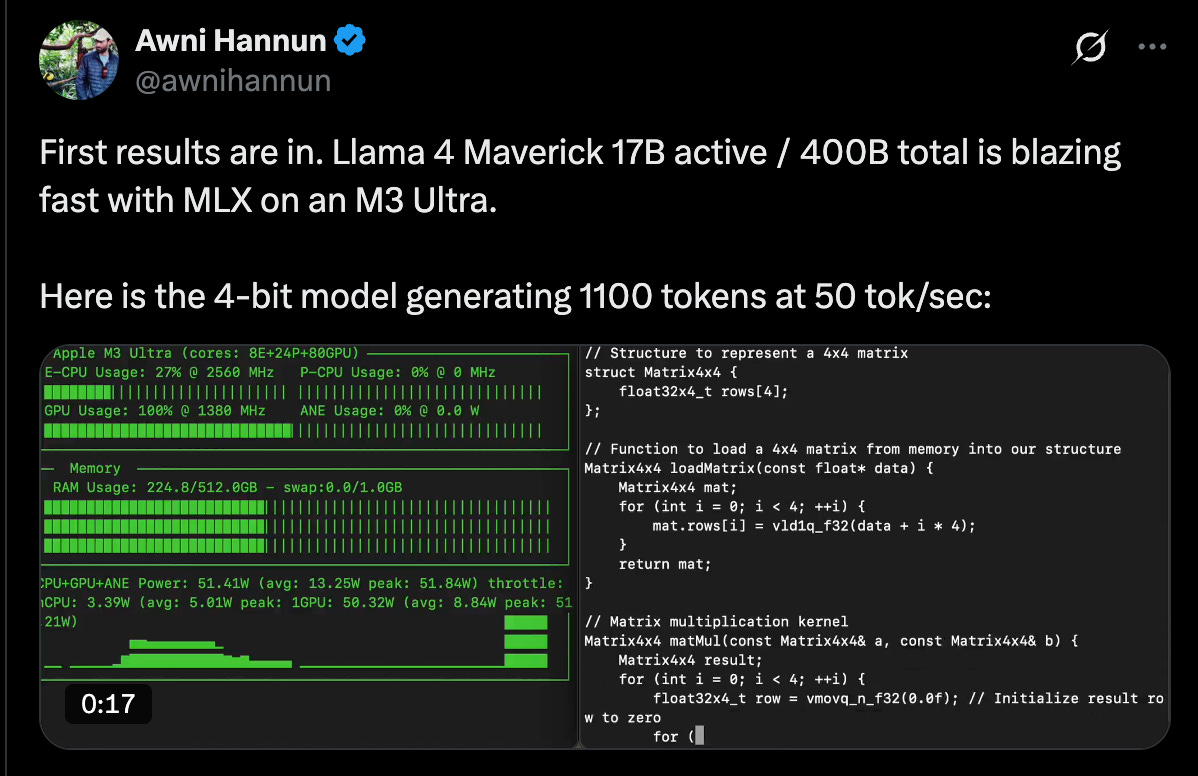
The open source community has generally been underwhelmed by Meta's release of the Llama 4 models so I was intrigued by this thread by a happy Mac owner.
They were able to run Maverick, the largest 400b variant, on their 512GB M3 Ultra Mac Studio without a problem since memory is plentiful on high-end Apple consumer hardware. Previously, they were left with a choice of running a higher quality, slower 32b-70b model vs. a lower quality, faster 8-14b model for their coding workflows. As a MoE model, Maverick only has 17b active parameters during inference, so from a speed standpoint it was close to the latter (as a reference, you can run 4-bit quantized Maverick can generate 1000 tokens at 50 tok/s on a M3 Ultra), but early tests showed quality comparable to the former.
This makes me wonder whether there is a regime where giant MoE models like Llama 4 help push out the quality/speed frontier for consumer hardware with sufficient memory even if they fall short of innovating at the leading edge of frontier model performance. As the next generation of consumer hardware with more unified memory is shipped (i.e. Apple's M series, Nvidia's DGX Spark, AMD's Halo Strix), that seems like it would still be pretty valuable.
MLX 🤝 CUDA
Apple is sponsoring the creator of Electron to experiment with a CUDA backend for MLX, Apple's ML framework tuned for Apple Silicon. This seems strange at first glance - if the whole point of MLX is to drive more development on top of Apple Silicon then why spend time on CUDA which is proprietary to Nvidia?
My guess is that while MLX has grown a lot in popularity, it is still handicapped by the fact that PyTorch is the higher level abstraction that most developers use to interface with CUDA on Nvidia GPUs. The average ML developer that wants to make sure they can target Nvidia, which dominates the GPU market, would need to juggle both PyTorch and MLX to work with both Nvidia and Apple. But, if MLX could target CUDA as well, then a ML developer could more seamlessly start off targeting Nvidia and then switch to Apple with the transition streamlined by MLX as the single abstraction layer. We'll see how this shakes out...
Small models 🤝 big models
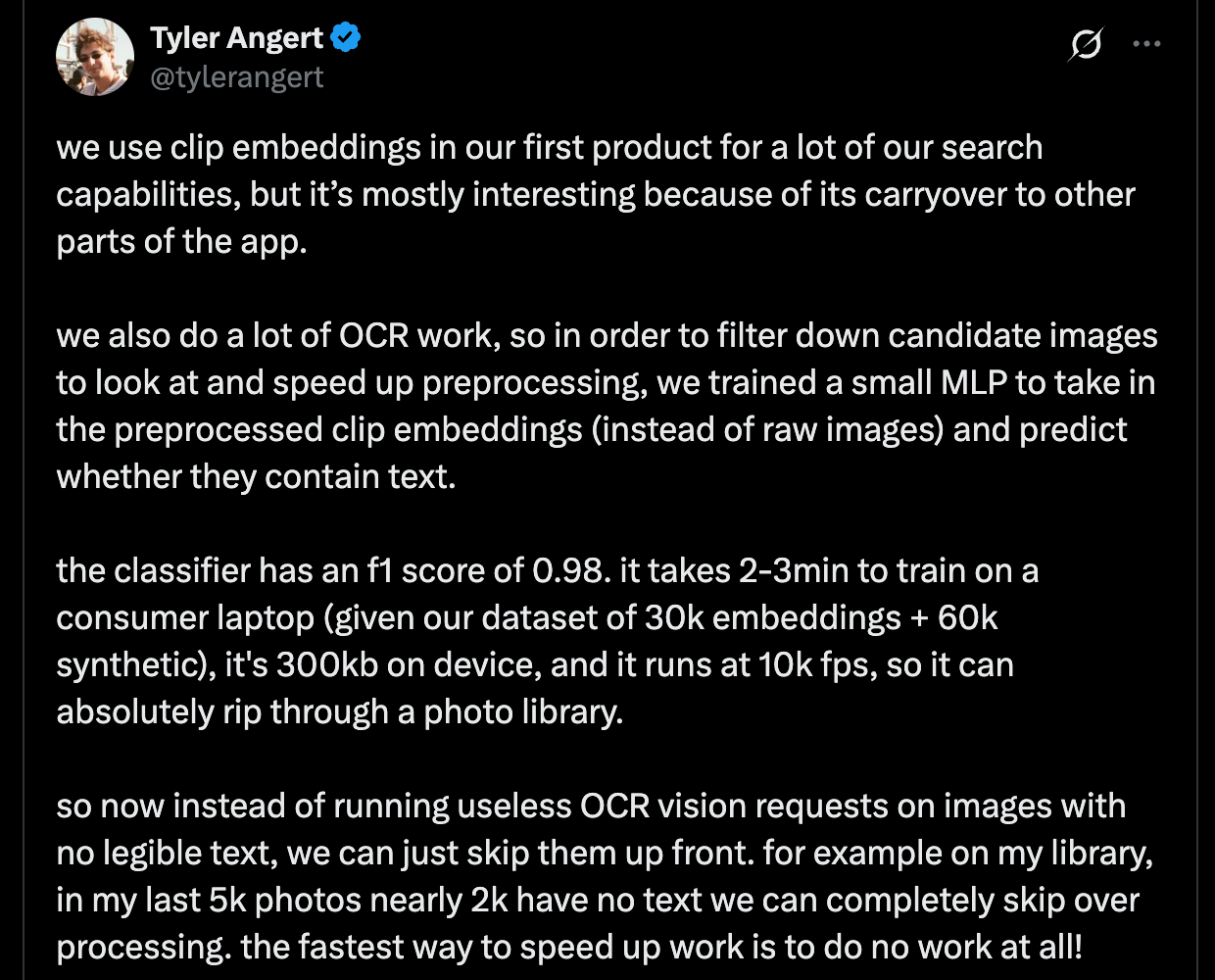
Tyler Angert shared some notes on how Patina is using local models trained on CLIP embeddings to predict whether images contain text to reduce the # of heavier OCR requests that need to be made - no need to OCR if you know that the image doesn't even have text.
I suspect that this pattern of using small, local models for fast, easier, high frequency tasks to reduce the number of calls to bigger models for heavier tasks will become increasingly useful especially as more capabilities trickle down into small models through distillation, quantization, etc.
Gemma 3 1b on iPhone 16
I've been playing with Gemma-3-1b (Q4) on my iPhone 16 via Pocket Pal which is built on top of the React Native bindings for llama.cpp. Limited knowledge, but it can certainly chit-chat endlessly at 46.84 tok/s. Local AI characters in your pocket will be a thing.
Gaussian Splatting with Scaniverse on iPhone 16
I was looking for an easy way to try Gaussian Splatting after seeing this, but I didn't want to deal with the setup of open source tools or subscribing to yet another service just to generate a single splat so I was pleased to stumble on Scaniverse (owned by Niantic) which supports free on-device splat generation.
Semantic search with MobileCLIP on iPhone 16

Queryable is a neat iOS app that uses Apple's MobileCLIP model to perform efficient mobile semantic search on images. Apple has had these types of capabilities for their own apps, but its interesting to see Queryable experiment with different interfaces for using the same capability - I can browse my Photos library simply by swiping down on a photo and clicking into the next most similar ones without any text input.